方法論特殊講義III
因果推論の考え方とランダム化比較試験
2025-08-15
講師紹介
実習
実習はRで行う。2日目のオンデマンド講義ではRの導入および使い方についても解説(復習レベル)する。
- 本講義の分析はExcel, SPSS, Stata, Julia, Pythonなどでも可能
- Jared P. Lander. 2017. R for Everyone: Advanced Analytics and Graphics (2nd Edition), Addison-Wesley Professional.(邦訳有り)
- 宋財泫・矢内勇生.『私たちのR: ベストプラクティスの探究』Web-book
- 無料のR入門書:Rを広く、深く勉強したい人におすすめ
宋のR環境
- macOS Sequoia 15.6
- R version 4.5.1 (2025-06-13)
- R > 4.3ならOK
- RStudio 2025.05.1+513
- スライド、サポートページ、実習用資料の執筆環境
- Quarto 1.7.33
- R package {quarto} 1.4.4

社会科学における因果推論の意味
Morgan and Winship (2014) Counterfactuals and Causal Inference: Methods And Principles For Social Research. Cambridge.
More has been learned about causal inference in the last few decades than sum total of everything that had been learned about it in all prior recorded history. (Gary King)


同時性
Simultaneity

原因と結果の間に双方向の因果関係が存在
- 例)お酒(原因; \(X\))とストレス(結果; \(Y\))の関係
- 酒を飲むとストレスが貯まる
- ストレス解消のために酒を飲む
- 酒を飲むとストレスが貯まる
- ストレス解消のために酒を飲む
- 酒を飲むとストレスが貯まる
- …
- \(\rightarrow\) 地獄のような無限ループ
\(\Rightarrow\) 酒がストレスに与える影響は?
見かけ上の相関
Spurious Correlation、擬似相関
- たまたま相関関係がある場合
- 例) メイン州の離婚率一人当たりマーガリンの消費量
見かけ上の相関
Spurious Correlation、擬似相関
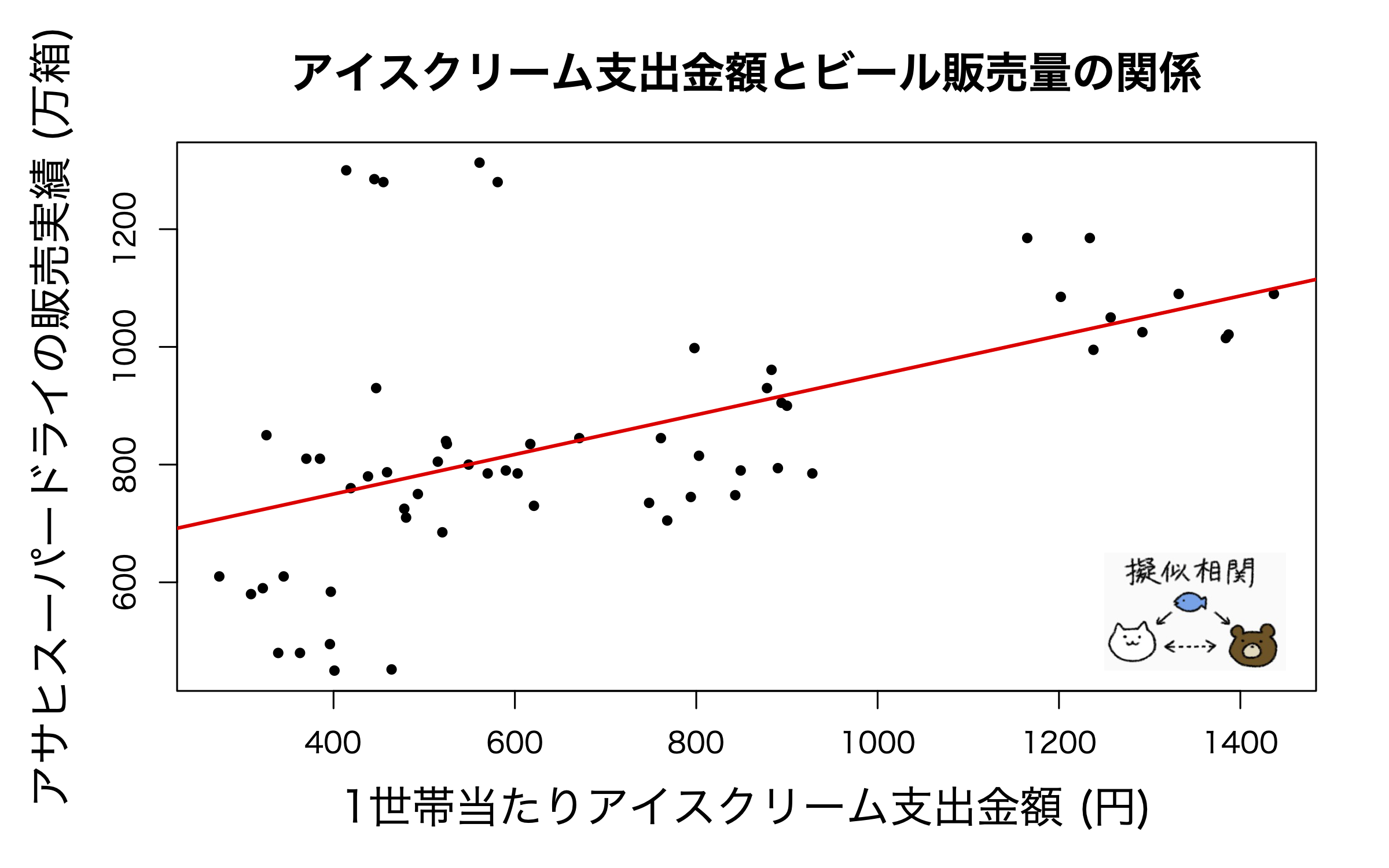
- 共通の要因からの影響
- 例) ビール消費量とアイスクリーム消費量
見かけ上の相関
Spurious Correlation、擬似相関
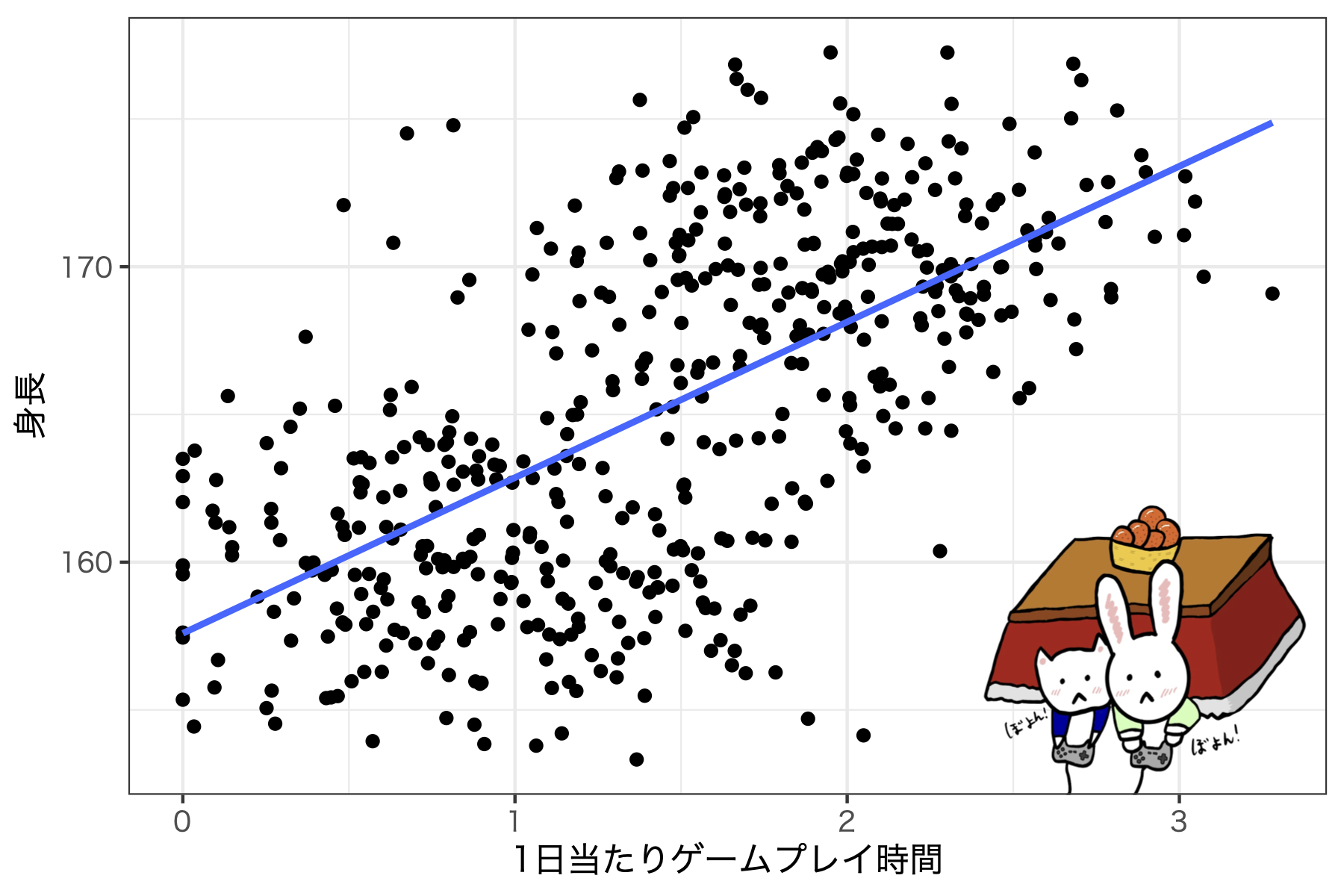
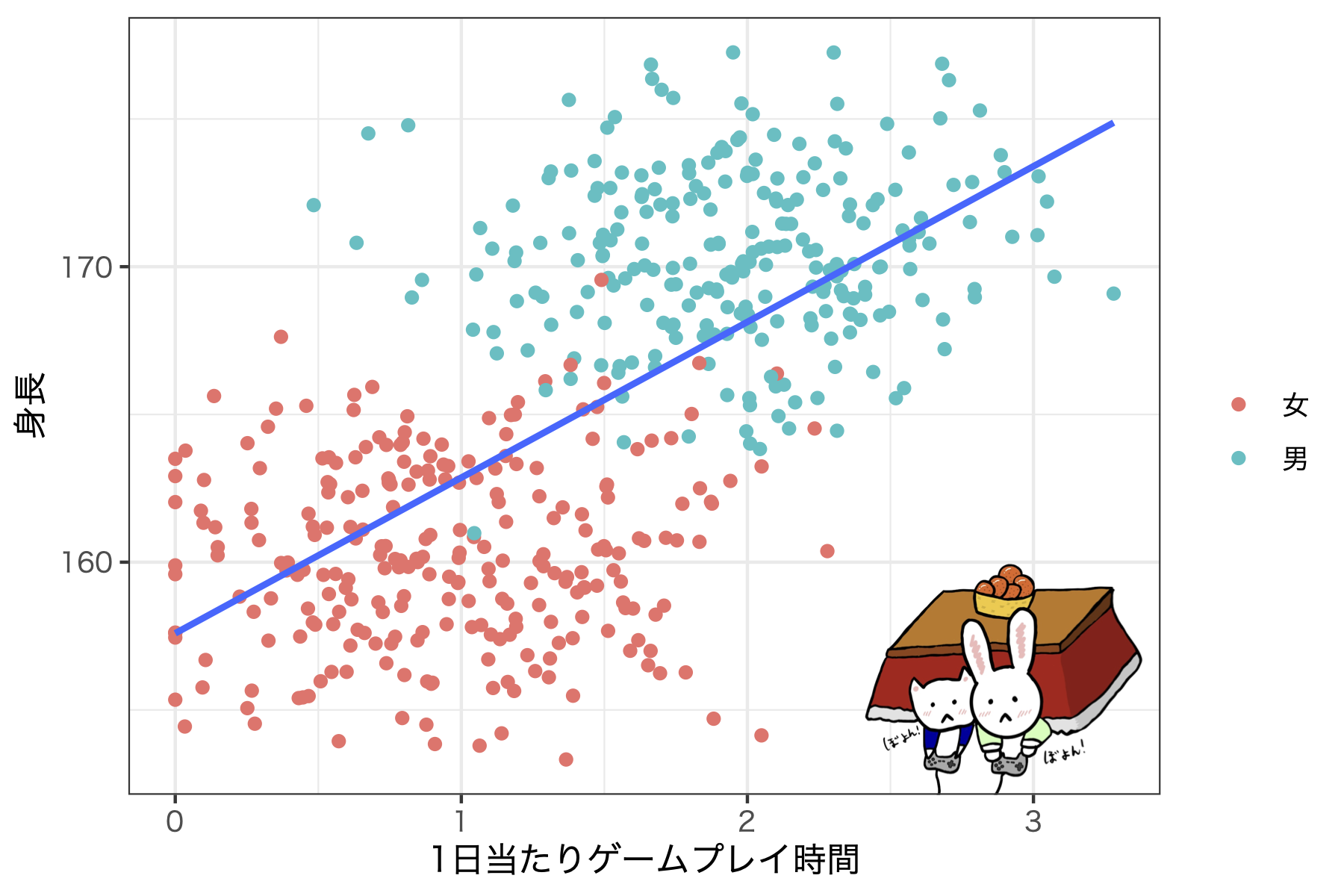
- 共通の要因からの影響
- 例) ゲームをやると身長が伸びる説
逆の因果
Reverse Causality
- 「人気だから4文字に略されるのか、4文字に略せるからヒットす るのか、どっちなんでしょうね」

欠落変数バイアス
Omitted Variable Bias
例) 真のモデルが\(Y = \beta_0 + \beta_1 \cdot X + \beta_2 \cdot Z + e\)の場合

- モデルに\(Z\)が含まれていなくても\(\beta_1\)の推定値は変化\(\times\)
- \(X\)と\(Z\)は独立(\(X \perp Z\))
- =\(X\)と\(Z\)の共分散が0(\(\sigma_{X, Z} = 0\))
欠落変数バイアス
Omitted Variable Bias
例) 真のモデルが\(Y = \beta_0 + \beta_1 \cdot X + \beta_2 \cdot Z + e\)の場合
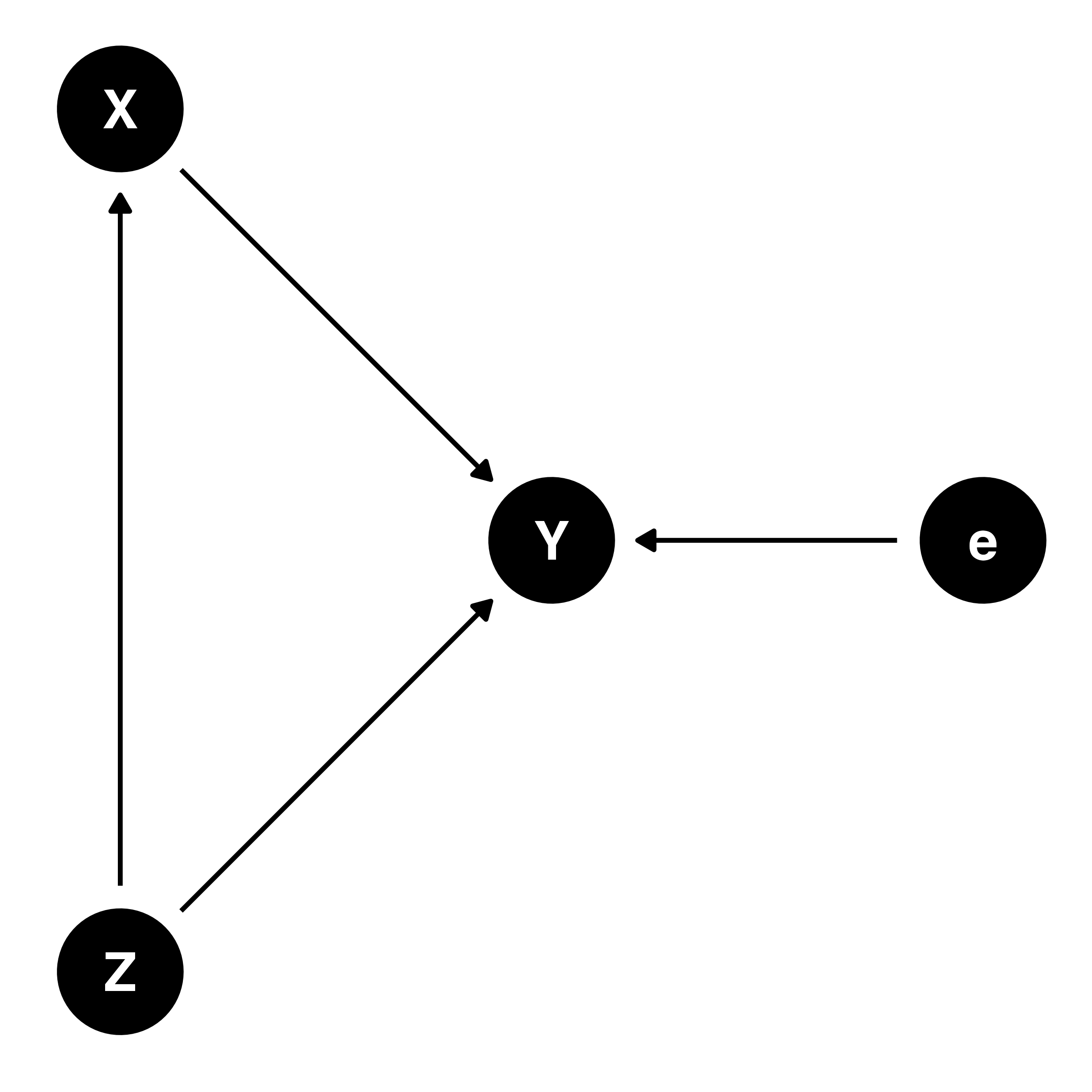
- モデルに\(Z\)が含まれていない場合、\(\beta_1\)の推定値にバイアス
- \(Z \rightarrow X\)の関係が存在
- \(\sigma_{X, Z} \neq 0\)
- \(\beta_1\)の真の値(=不偏推定量)を推定するためには\(X\)と\(Y\)両方と相関する変数すべてが必要
- そもそも、「真の値」とは?
- \(X\)と\(Y\)両方と相関するすべての変数は特定可能? 測定可能?
- \(\rightarrow\) データ分析から得られた結果はあくまでも「分析モデルが想定している世界」のものに過ぎない
- 定量的手法は反証可能性を高めやすい手法(=科学的な手法になりやすい)であって、科学そのものを保障するものでもなく、得られた結果が真理であることを保障するものでもない。
因果推論の根本問題
- \(Y_i(T_i = 1)\)か\(Y_i(T_i = 0)\)、片方のみしか観察できない状態においてITEから因果効果を推定することは不可能
- 因果推論の根本問題(The Fundamental Problem of Causal Inference)
- 解決方法
- もう一回、過去に戻って異なる処置を行う

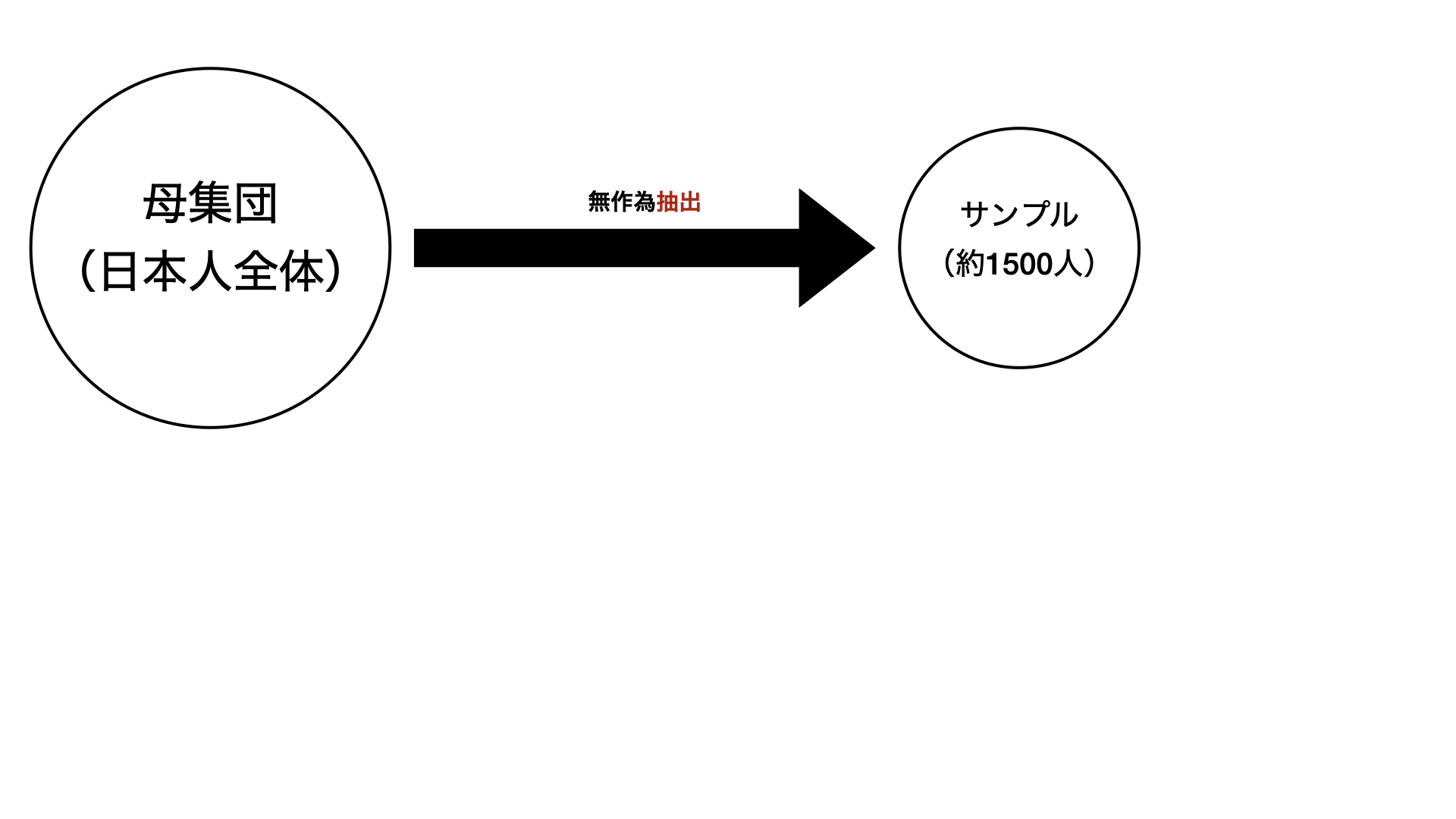
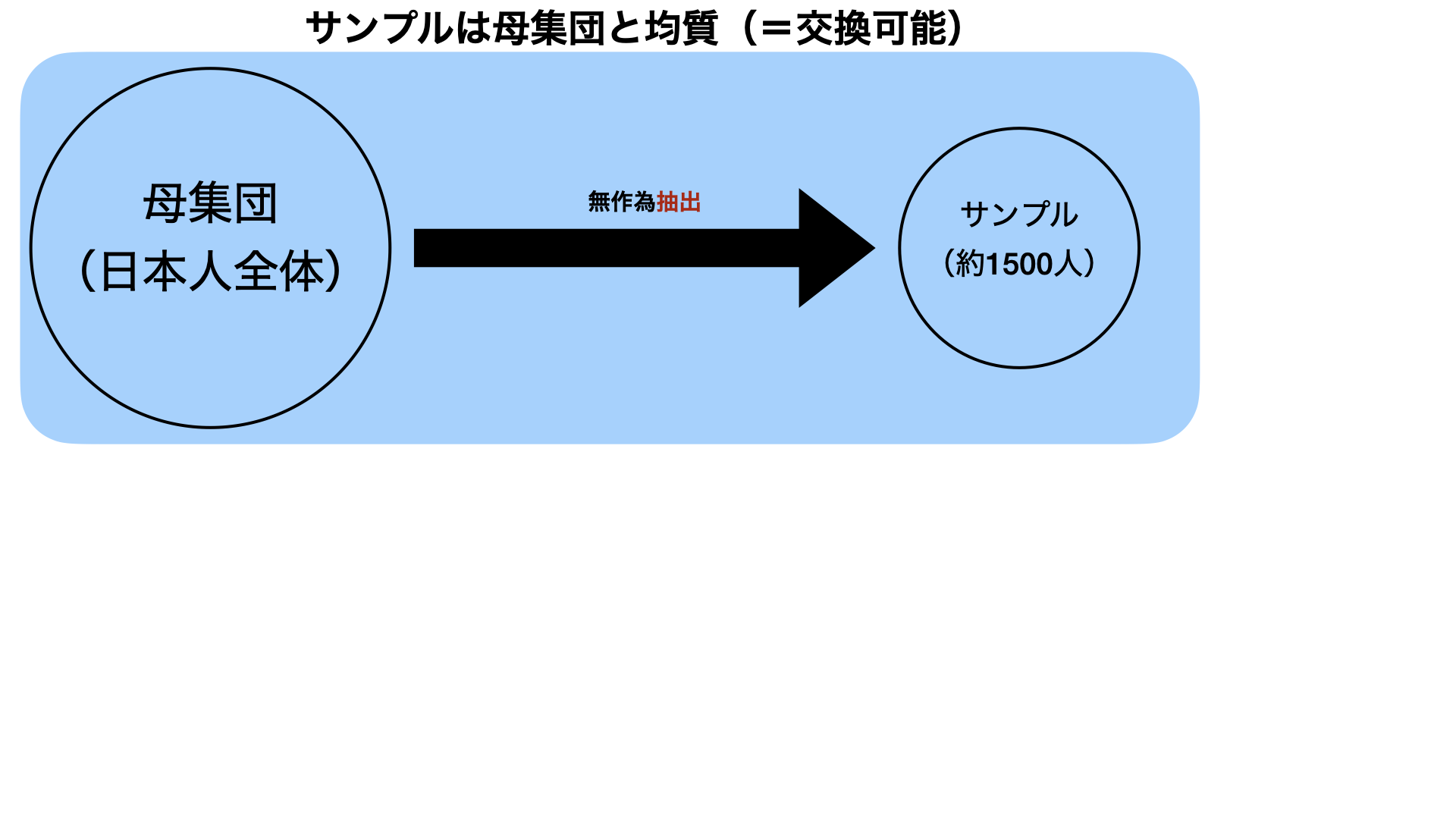
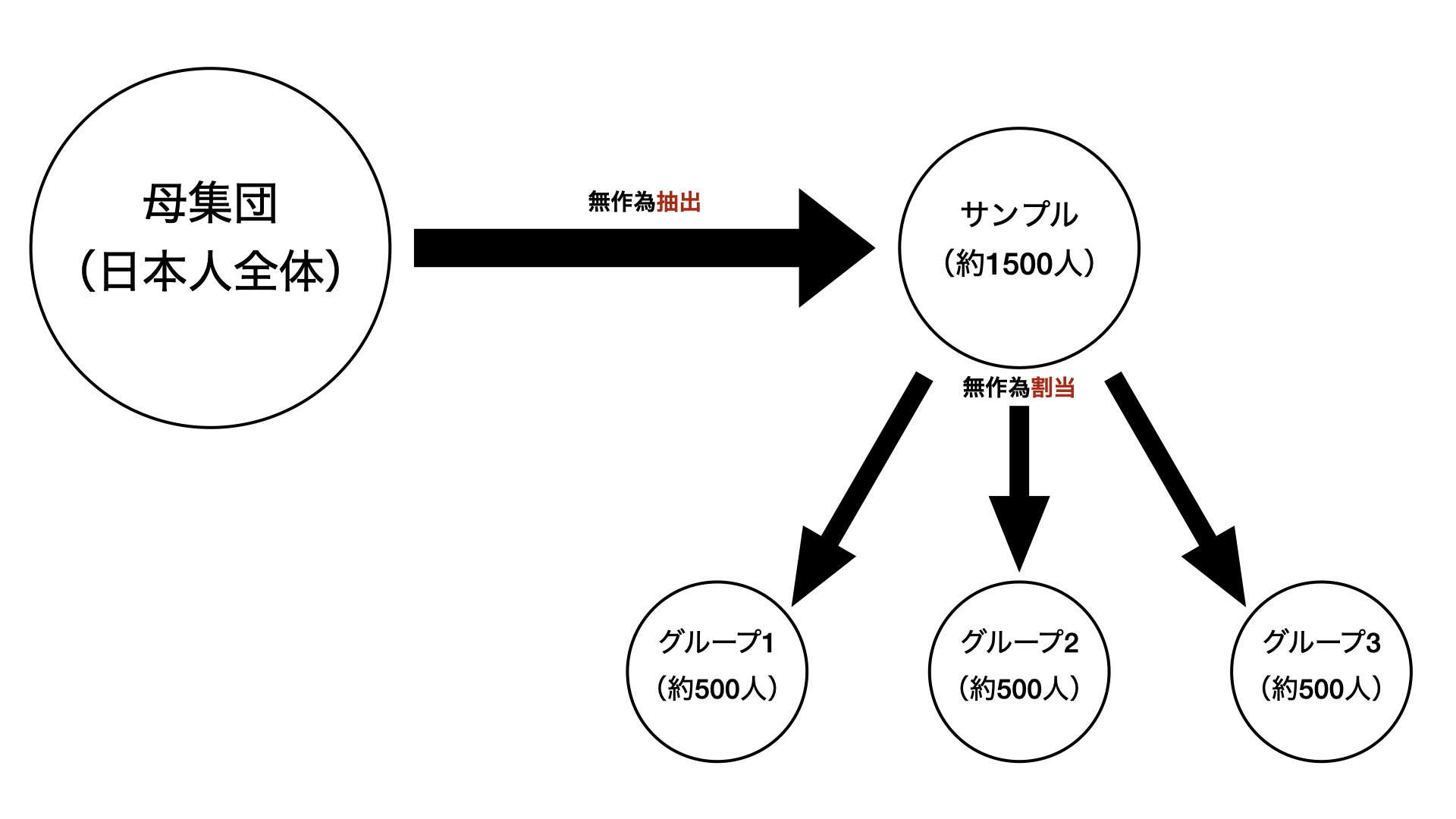
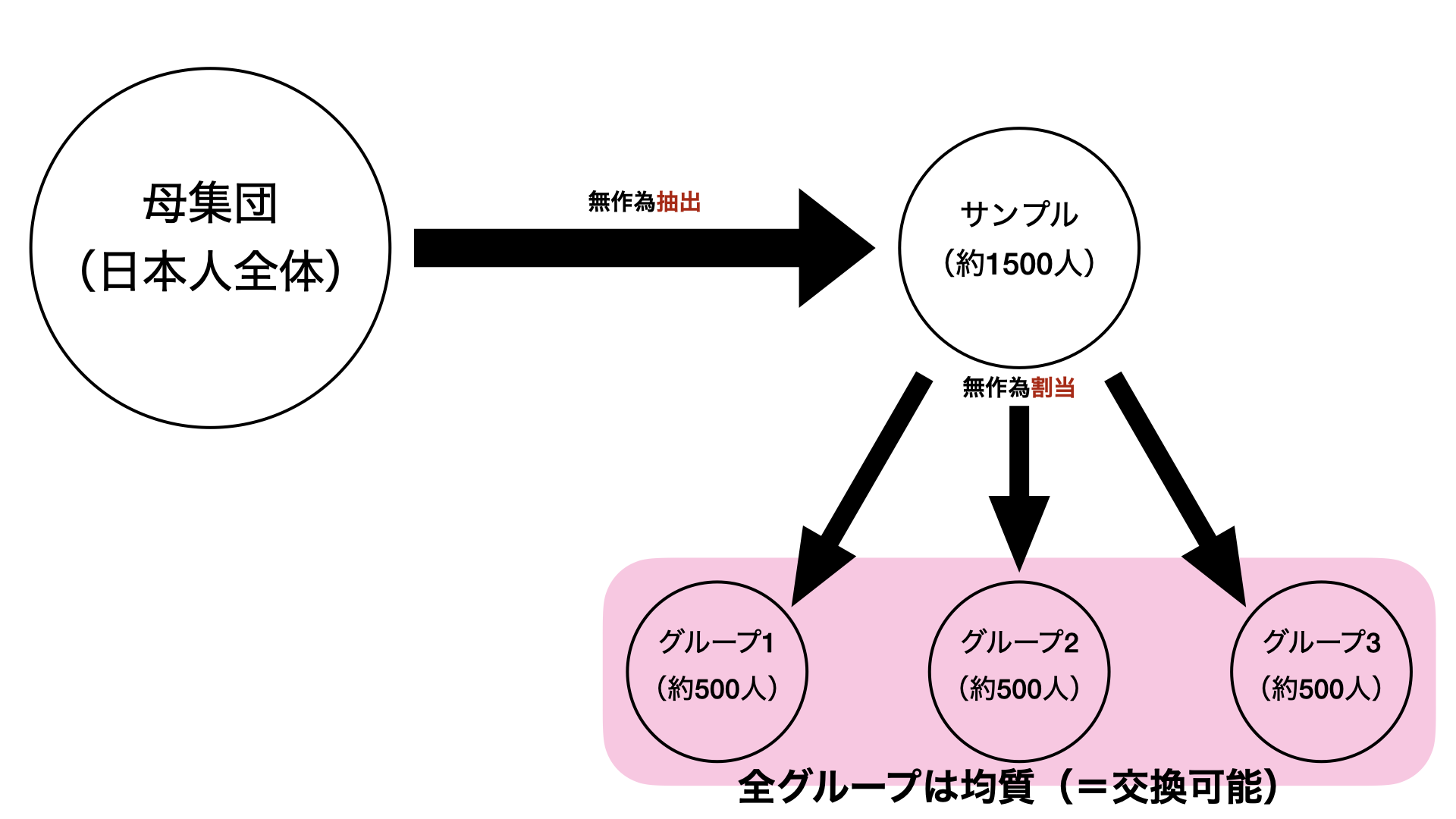
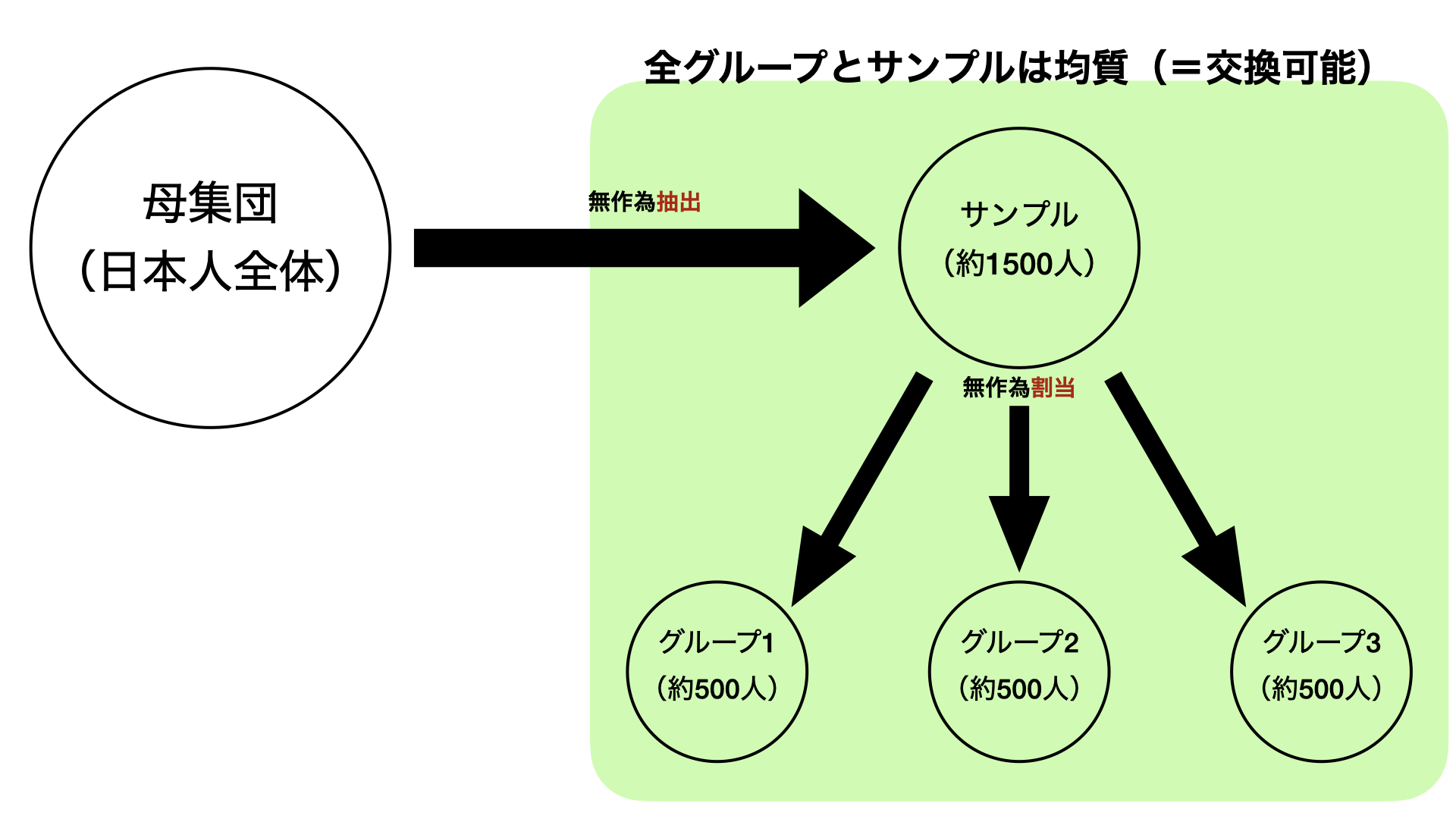
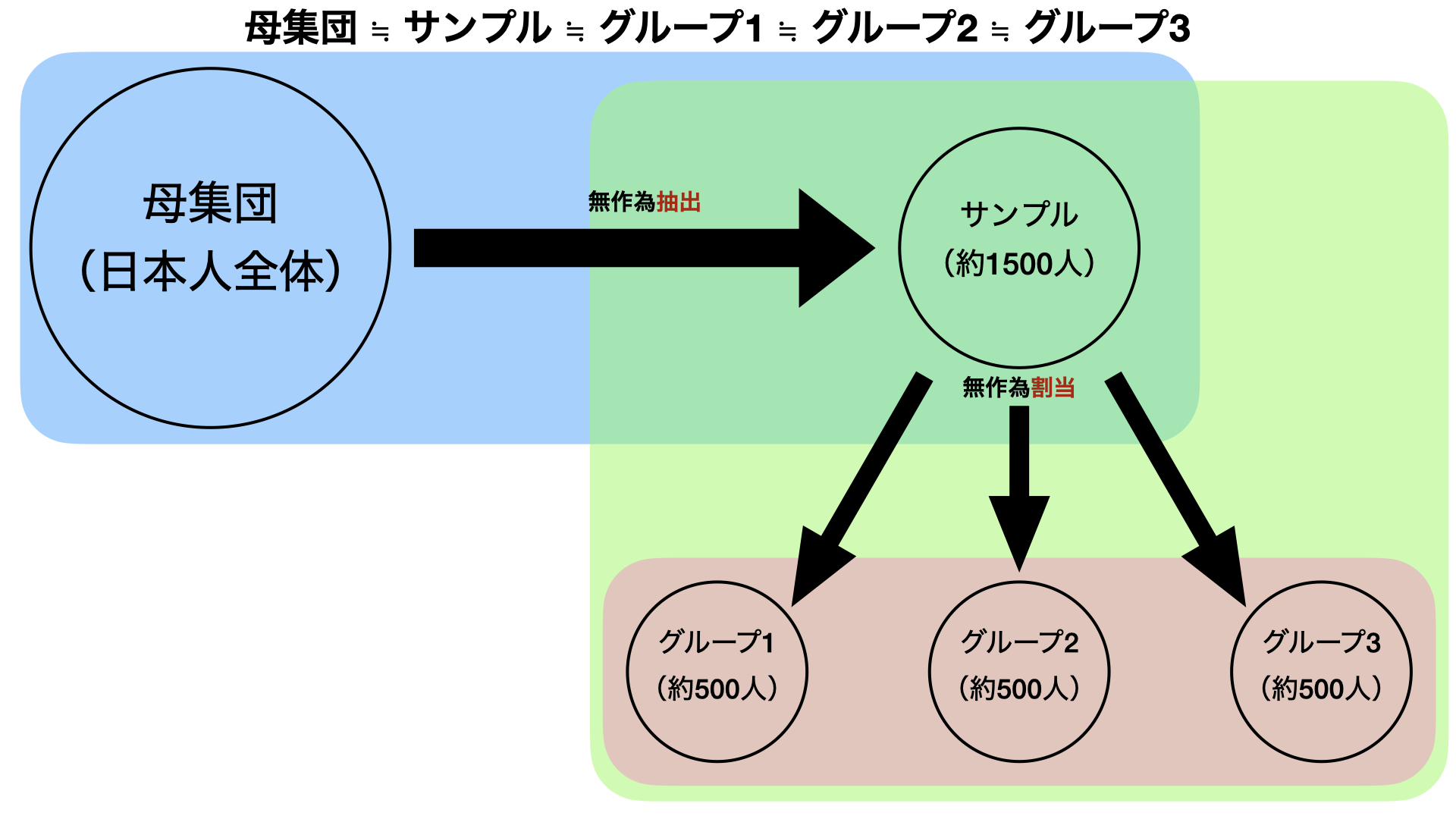
無作為抽出と無作為割当
- 無作為抽出によってサンプル(標本)と母集団が交換可能(実はここが難しい)
- 無作為割当によって各グループとサンプルに交換可能(= 各グループ間で交換可能)
- 無作為抽出&無作為割当によって各グループと母集団が交換可能(グループへの刺激 = 母集団への刺激)


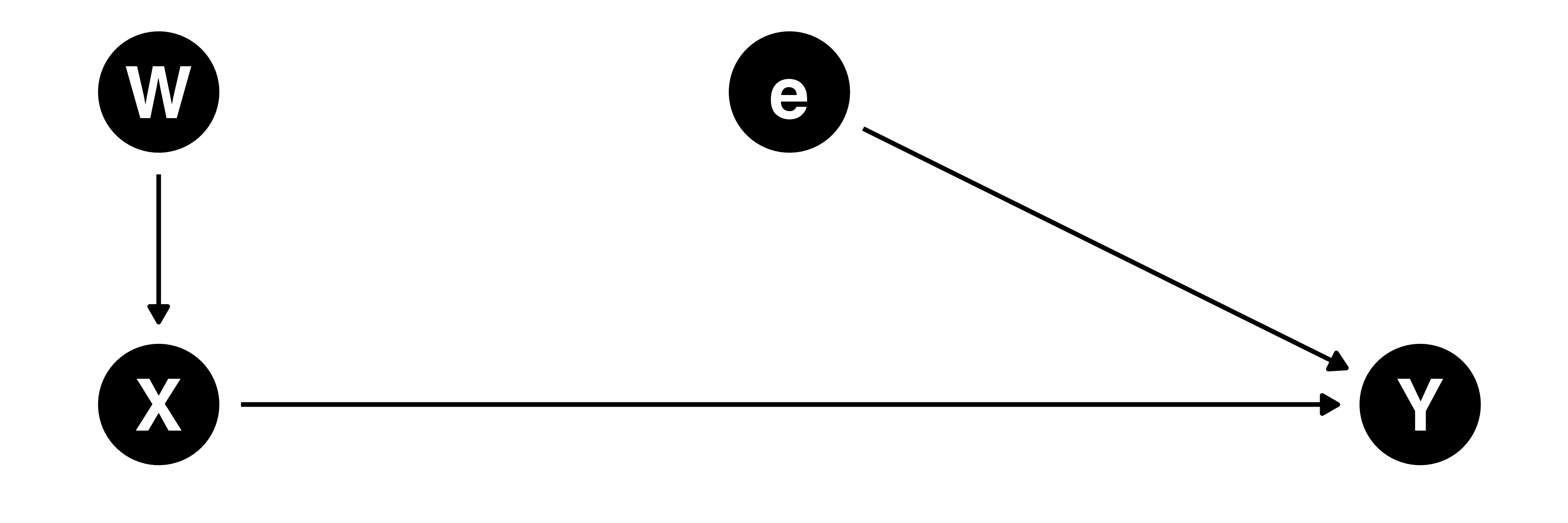
データ生成過程への介入
以下のデータ生成過程を仮定
\[ \mbox{Income} = \beta_0 + \beta_1 \cdot \mbox{Quant} + \varepsilon \]
- Income:10年後の年収(\(\mbox{Income} \in [0, \infty)\))
- Quant:ソンさんの講義を履修したか否か(\(\mbox{Quant} \in \{0, 1\})\))
- 誤差項(\(\varepsilon\))には「やる気」や「真面目さ」が含まれるため、Quantと相関がある(\(\rightarrow\) 内生性)
- 無作為割当で受講有無を決めると、「やる気」や「真面目さ」はQunatと無関係(= 独立)になる
- 例) 受講有無をコイン投げ(\(W\))で決める場合、コインの結果は誤差項(やる気や真面目さ)と独立(ただし、全員がコイン投げの結果に従うと仮定)
- \(\Rightarrow\) 内生性がなくなる!

内生性の可能性

- 誤差項(\(\varepsilon\))には教育水準、親の所得、居住地などが含まれる可能性
- 実際に人種と上記の要因には相関あり
- 人種(処置)と誤差項(\(\varepsilon\))間の相関関係 \(\rightarrow\) 内生性
- 黒人が採用されなかった場合…
- 黒人だから? \(\leftarrow\) 人種差別\(\bigcirc\)
- 教育水準が低いから \(\leftarrow\) 人種差別\(\times\)
\(\Rightarrow\) 内生性がある限り、因果効果の識別は困難
\(\Rightarrow\) ケースによって政策的含意が変わる。
バランスチェック
無作為割当が行われているか否かを確認
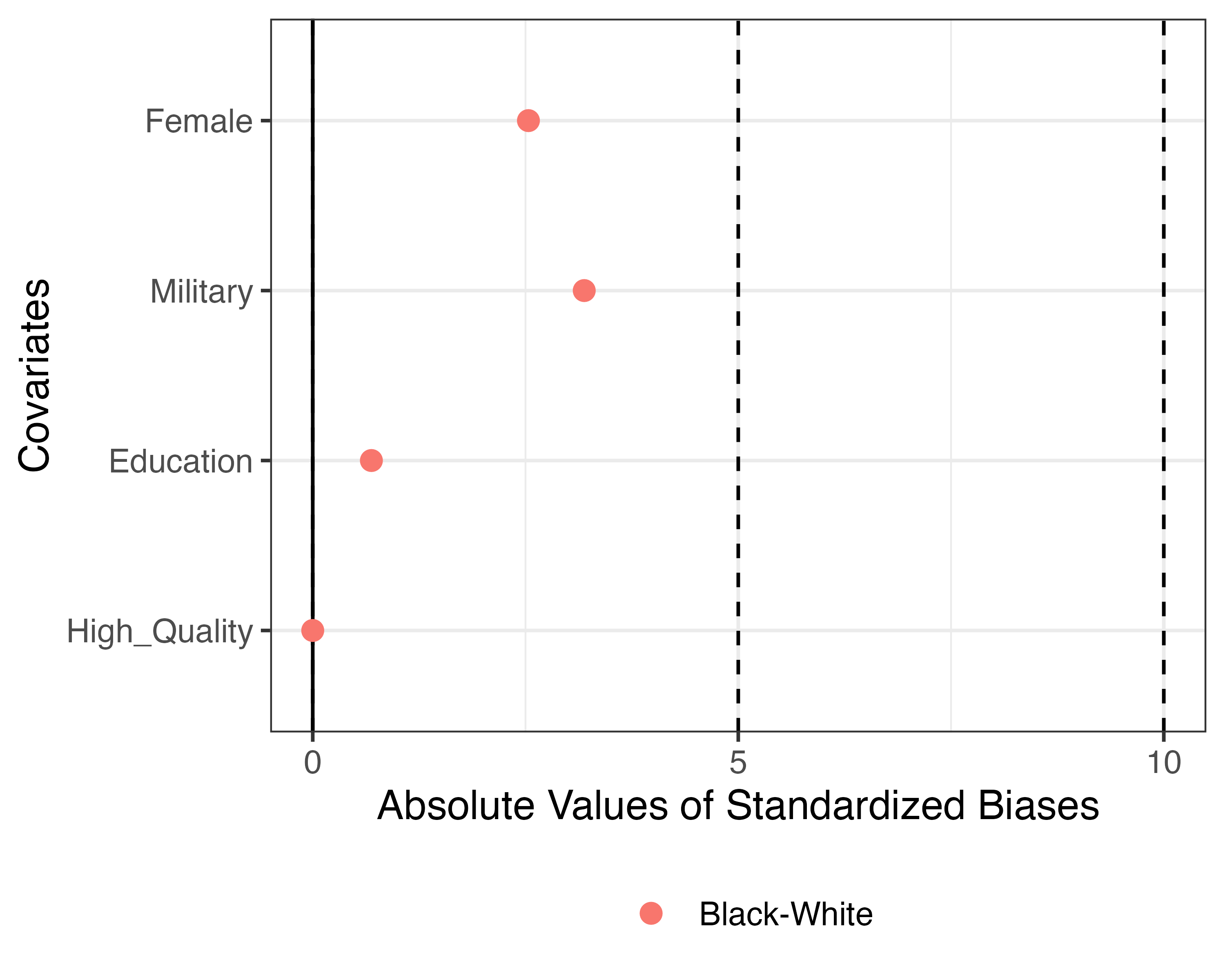
標準化差分を使用
- Standardized Bias(Standardized Difference)
- サンプルサイズの影響\(\times\)
- 統計的検定ではない
- \(t\)検定、ANOVA、 \(\chi^2\)検定は\(\times\)
- バランスチェックに統計的有意性検定は使わない
- {cobalt}、{BalanceR}など
バランスチェック
処置が複数の場合、組み合わせごとに標準化差分を計算
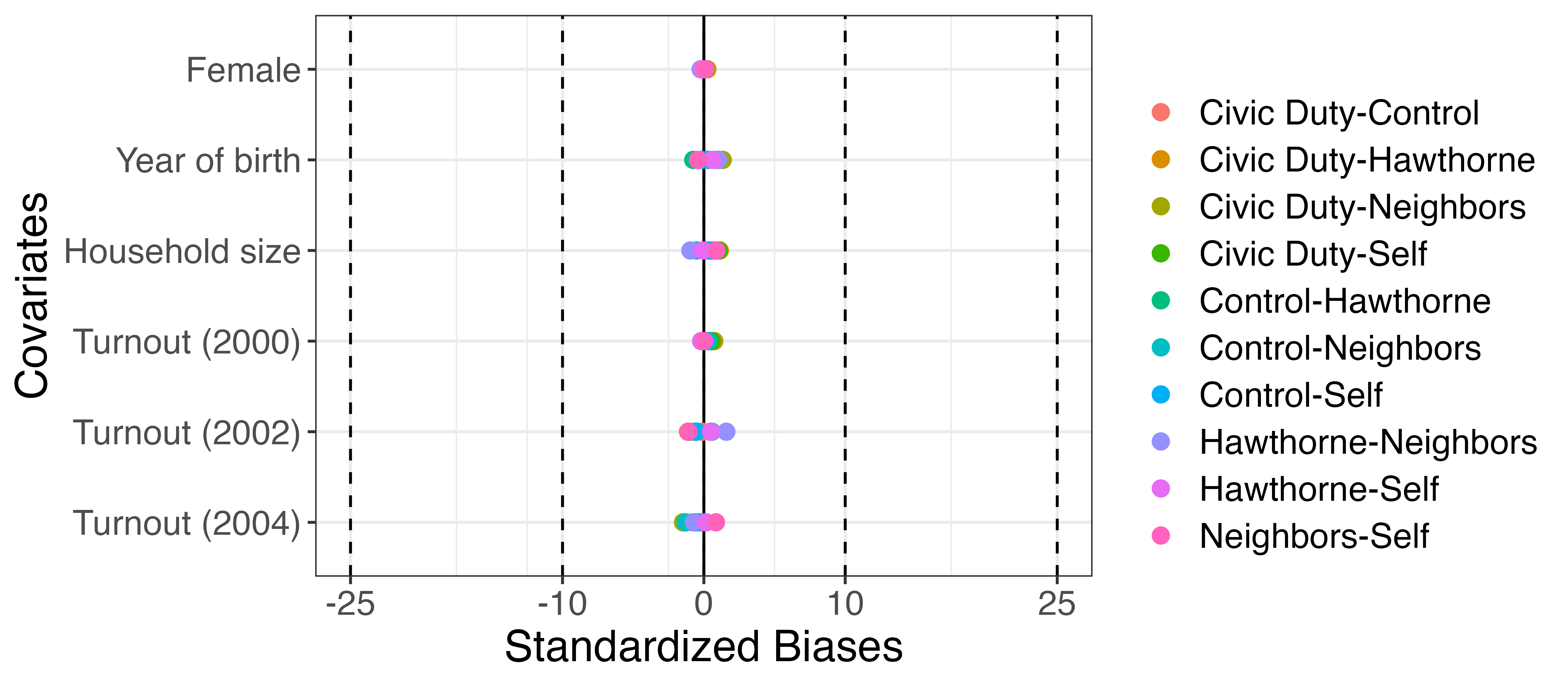
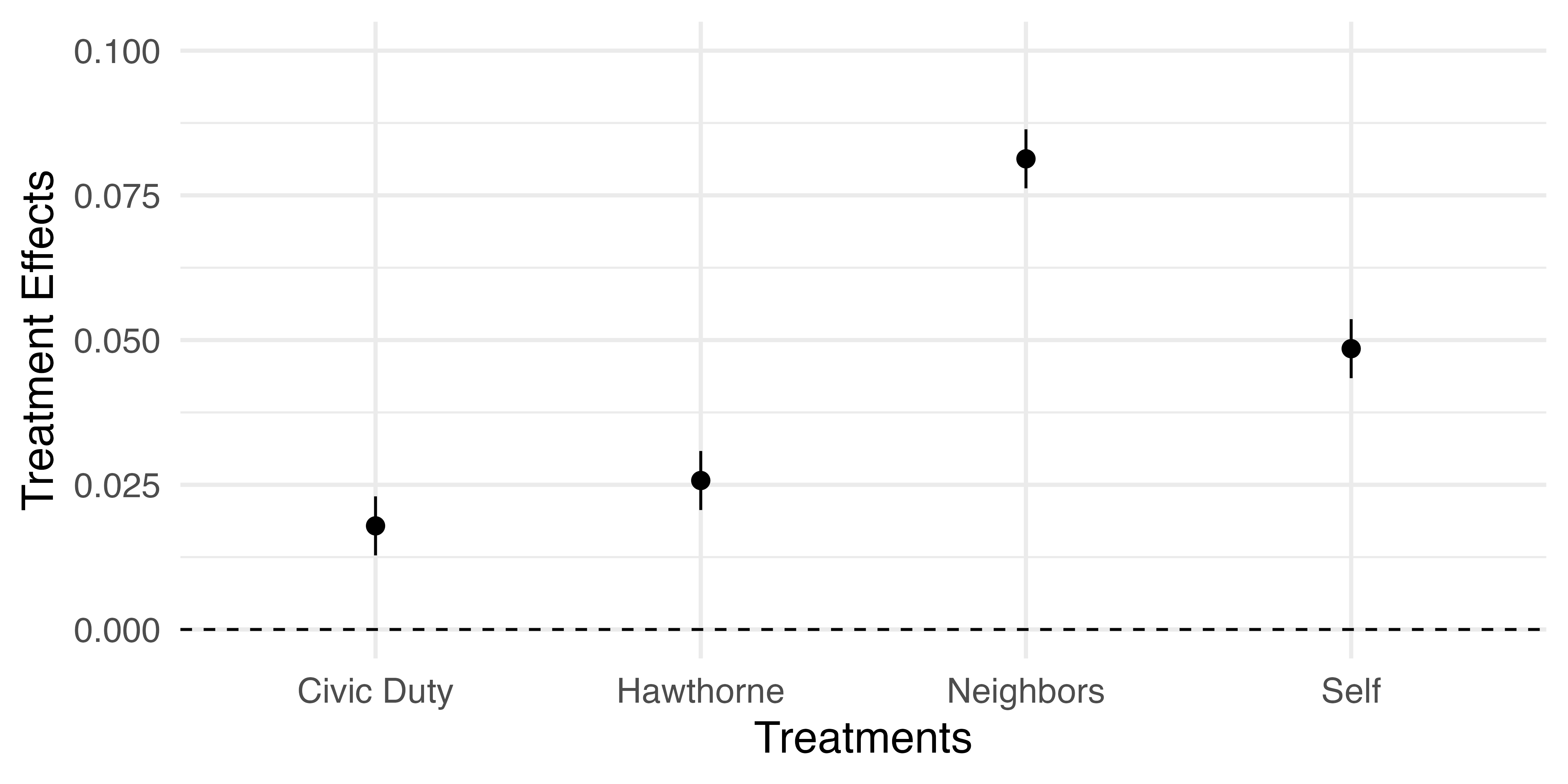
処置効果の可視化