ミクロ政治データ分析実習
12/ 可視化(2)
棒グラフの必須要素
棒グラフを作成する際に必要な最低限の情報
x: 棒の横軸上の位置 (大陸)y: 棒の高さ (人間開発指数の平均値)
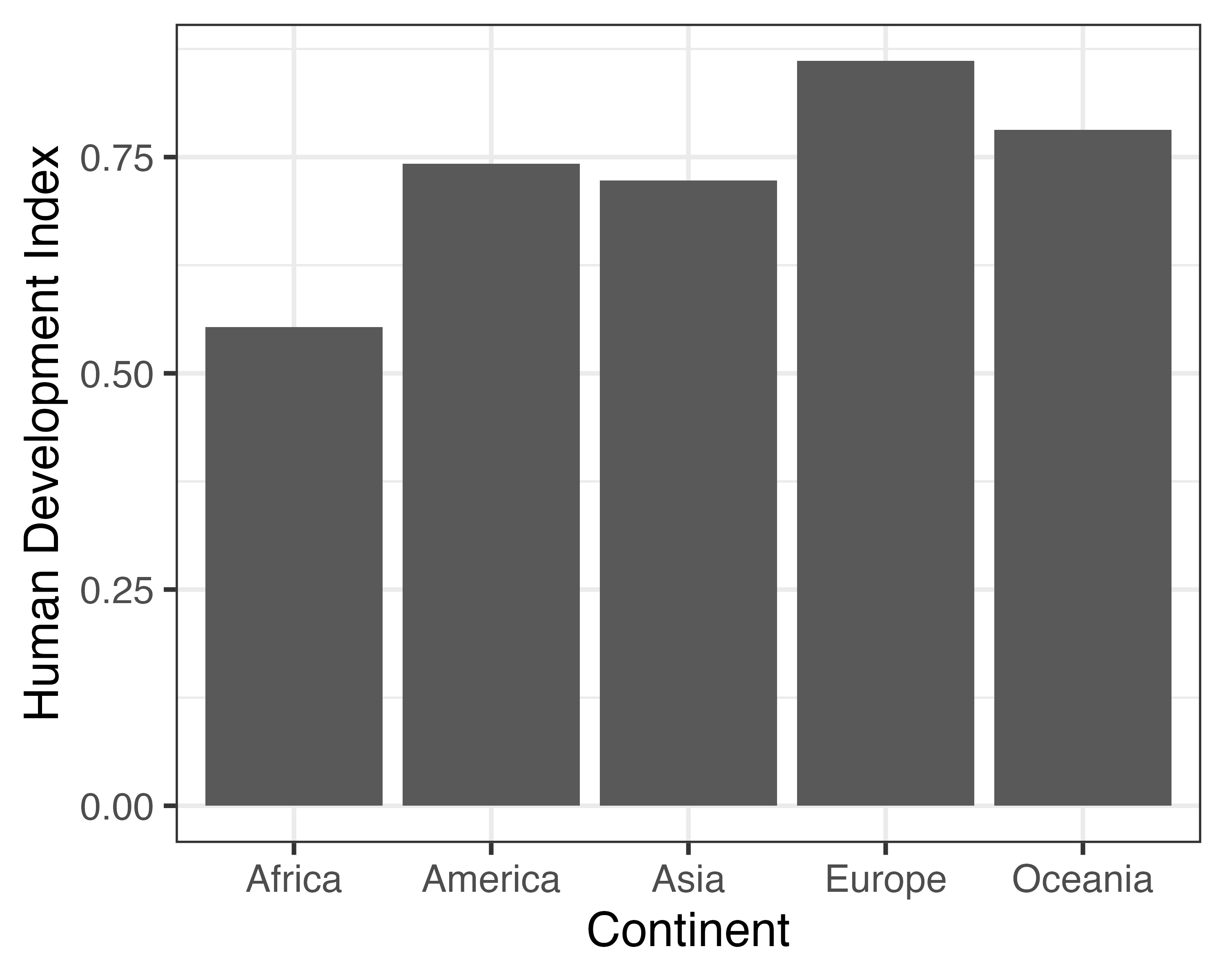
y: 棒の縦軸上の位置 (大陸)x: 棒の長さ (人間開発指数の平均値)
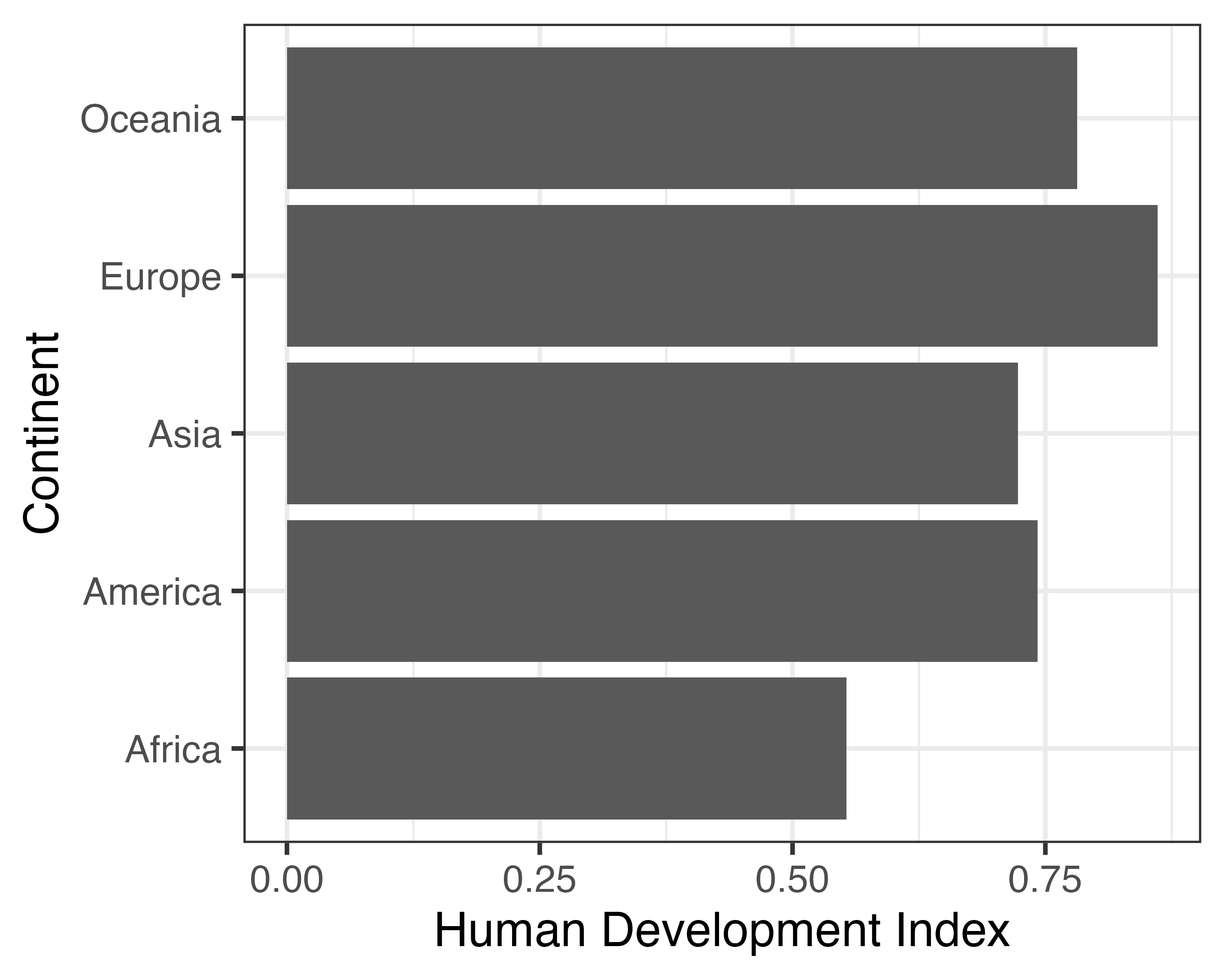
とりあえず作図してみよう
- 使用する幾何オブジェクト:
geom_col() - マッピング要素(幾何オブジェクト内に
aes())- 棒の横軸上の位置は大陸(
Continent)を意味する - 棒の高さは人間開発指数の平均値(
HDI)を意味する
- 棒の横軸上の位置は大陸(

日本語の使用(2)
Step2: 図のラベルを修正(labs())

棒の並び替え
アルファベット順に並べ替えたい場合

便利な関数: fct_inorder()
{forcats}のfct_inorder()関数({forcats}は{tidyverse}の一部)
- factor化を行い、各要素順番を表で登場した順番とする

作図

次元の追加
aes()内にfill = Continentを追加

棒の位置をずらす
geom_col()内にposition = "dodge"を指定(aes()の外)

凡例の位置調整
theme()内にlegend.position = "bottom"を指定
- デフォルトは
"right"("top"は上段;"none"は削除)

もう一つの方法:マッピングの交換
- 前ページの場合、「ある政治体制内の大陸の分布」を知ることに特化
- 「ある大陸内の政治体制の分布」を見るには? \(\rightarrow\)
xとfillを交換

もう一つの方法:ファセット分割
- 色分けを出来る限り抑えたい
facet_wrap(~ 分割の基準となる変数名)

値ラベルの回転
値ラベルが長すぎる場合、ラベルを回転することで重複を避ける
- 覚える必要はなく、必要に応じてググる(
theme()レイヤーはかなり複雑)

マッピング交換でも解決可能
xとyを交換しても良い

ヒストグラムの棒が持つ情報
棒の横軸上の位置と高さ
- {ggplot2}の場合、ヒストグラムを出力する変数を
xにマッピングするだけで、自動的にヒストグラムを生成
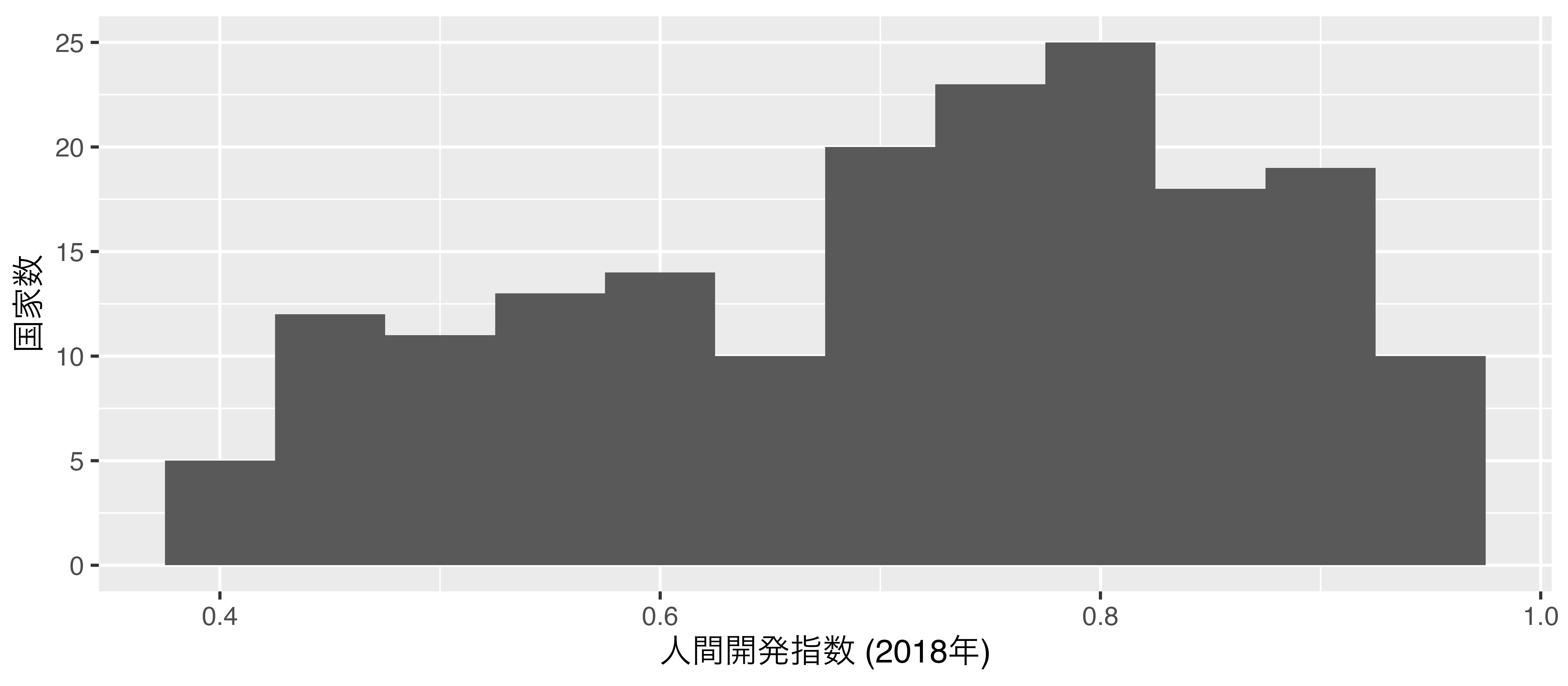
ヒストグラムの作成
geom_histogram()を使用: マッピングはxのみ

棒の数を調整する
geom_histogram()内、aes()の外にbins引数を指定

棒の幅を調整する
geom_histogram()内、aes()の外にbinwidth引数を指定

棒の枠線を入れる
geom_histogram()内、aes()の外にcolor引数を指定

横軸のスケール調整
scale_x_continuous()を使用 (xをyに変えると縦軸修正)
breaks引数: 目盛りの位置 /labels引数: 目盛りのラベル

次元の追加(ファセット分割)
大陸ごとのHDI_2018のヒストグラム: ファセット分割を使用

次元の追加 (色分け)
position = "identity"とalpha = 0.5で可能であるが、非推奨
alpha = 1の場合、棒が不透明であるため、0.5程度に調整

ベクトルとビットマップ
ベクトル画像を推奨するが、使用するワードソフトによってはPDFの図の埋め込みができない場合もある。
- 本講義では高解像度の
.png形式の保存方法について解説する。
ベクトル画像
.pdf、.svgなど- 推奨はPDF形式
- 拡大しても図が綺麗なまま
- 複雑な図であれば、ファイルのサイズが大きくなる

ビットマップ画像
.png、.bmp、.jpg(=.jpeg)など- 推奨はPNG形式
- 拡大すると図がカクカクする
- 高い解像度(DPI)にすると、拡大しても綺麗だが、ファイルサイズに注意
- 図が複雑でも、ファイルサイズが比較的安定
