ミクロ政治データ分析実習
14/ 可視化(3)
散布図の必須要素
散布図を作成する際に必要な最低限の情報
データにフリーダムハウス・スコアと人間開発指数の列が必要
x: 点の横軸上の位置- フリーダムハウス・スコア
y: 点の縦軸上の位置- 人間開発指数
- 原因と結果の関係(因果関係)が考えられる2変数の場合、原因を横軸、結果を縦軸にする。
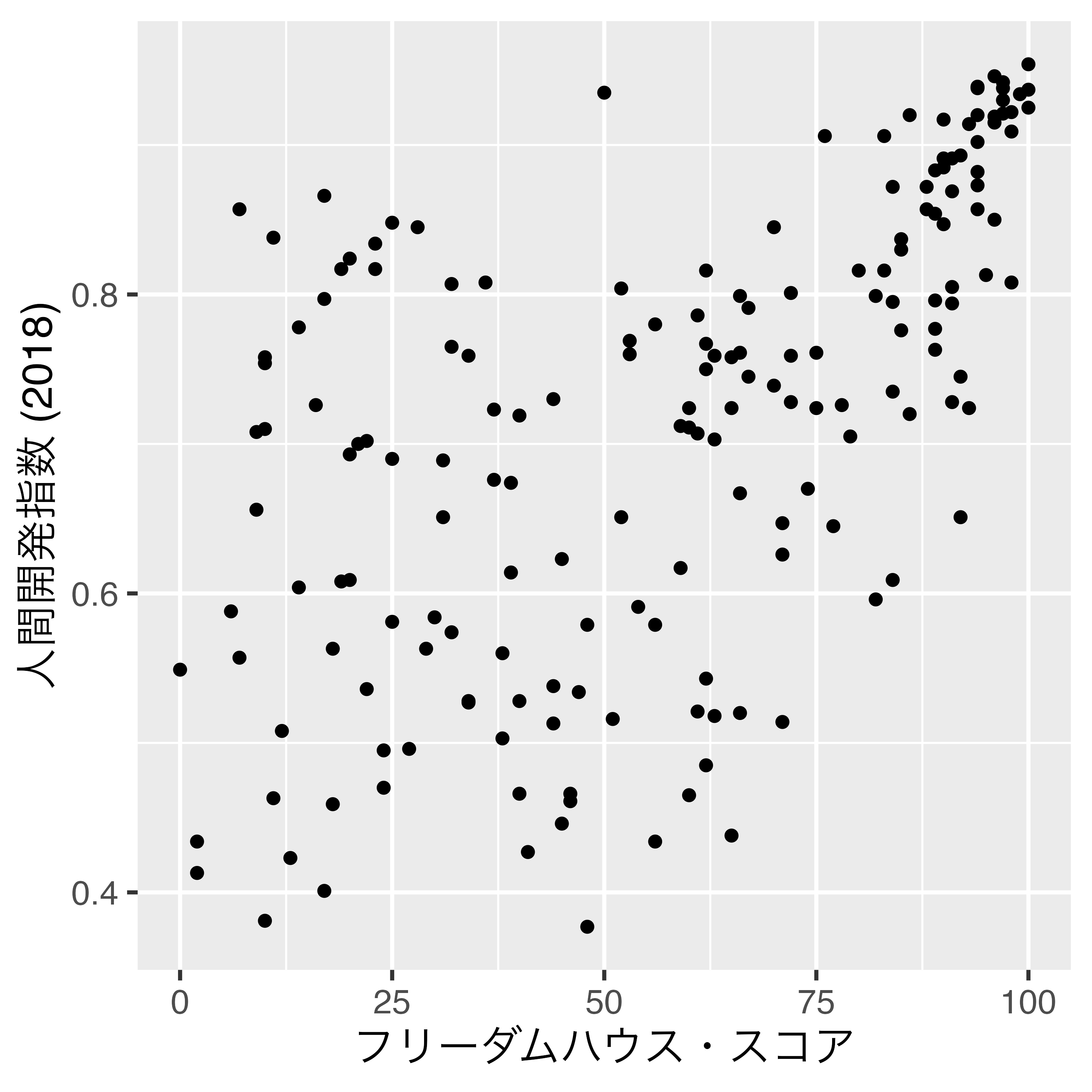
散布図の作成 (1)
幾何オブジェクトはgeom_point()を使用

散布図の作成 (2)
ラベル修正 / 必要に応じてカスタマイズ

5次元の散布図
各点はフリーダムハウス・スコア、人間開発指数、人口(対数変換)、大陸、OECD加盟有無の情報を持つ
df |>
mutate(OECD = if_else(OECD == 1, "Member", "Non-member")) |>
ggplot() +
geom_point(aes(x = FH_Total, y = HDI_2018, color = Continent,
size = Population, shape = OECD), alpha = 0.65) +
scale_size_continuous(trans = "log10") +
labs(x = "Freedom House Score", y = "Human Development Index (2018)",
size = "Population (log)") +
theme_gray()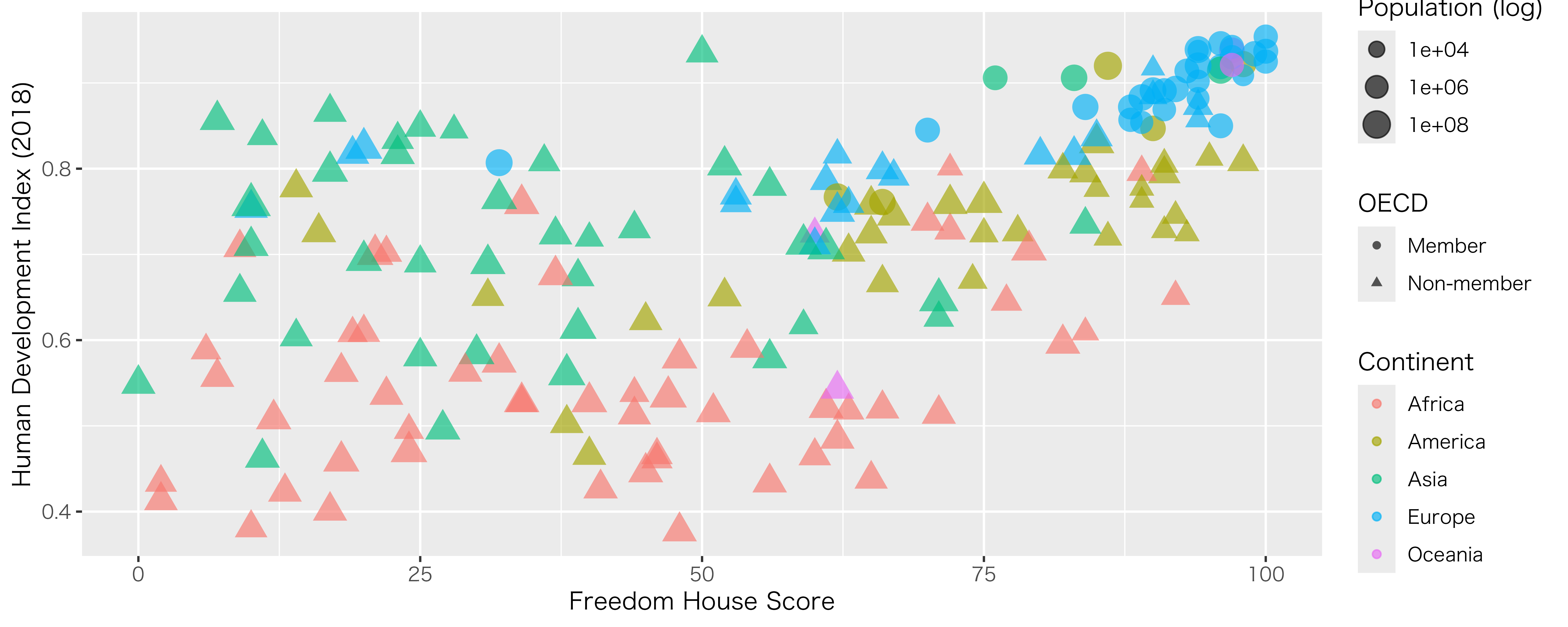
色分けの例
aes()の内部にcolor = 色分けする変数を指定
HighIncome変数を作成し、PPP_per_capitaが2万以上なら"高"、未満なら"低"HighIncome値に応じて点の色分けを行う(color = HighIncome)- 点の大きさは2とする(全体に適用させるため、
aes()の外側に指定) labs()内で凡例タイトルを修正; 凡例を下側へ移動
scatter_plot1 <- df |>
drop_na(FH_Total, HDI_2018, PPP_per_capita) |>
mutate(HighIncome = if_else(PPP_per_capita >= 20000, "高", "低")) |>
ggplot() +
geom_point(aes(x = FH_Total, y = HDI_2018, color = HighIncome),
size = 2) +
labs(x = "フリーダムハウス・スコア", y = "人間開発指数 (2018)",
color = "一人当たりPPP GDP") +
theme(legend.position = "bottom")
色のカスタマイズ
colorにマッピングされている変数(HighIncome)が離散変数
scale_color_manual()を使用(引数はvalues = c("値1" = "色1", "値2" = "色2", ...))

色の見本 (一部)

shapeの見本
shapeで指定(デフォルトはshape = 19)
- 黒の部分は
color、グレーの部分はfill(またはbg)で調整- 21と22の場合、枠線は
color、内側の色塗りはfill
- 21と22の場合、枠線は
- 0〜14の場合、中身が透明

折れ線グラフの必須要素
折れ線グラフを作成する際に必要な最低限の情報
データに日と新規感染者数の列が必要
x: 線の傾きが変化し得る点の横軸上の位置- 日
y: 線の傾きが変化し得る点の縦軸上の位置- 100万人当たり新規感染者数
- 散布図とほぼ同じ
- ただし、線が2つ以上の場合
groupsが必要- 点をグループ化しないと、どの点を繋げば良いかが分からないため
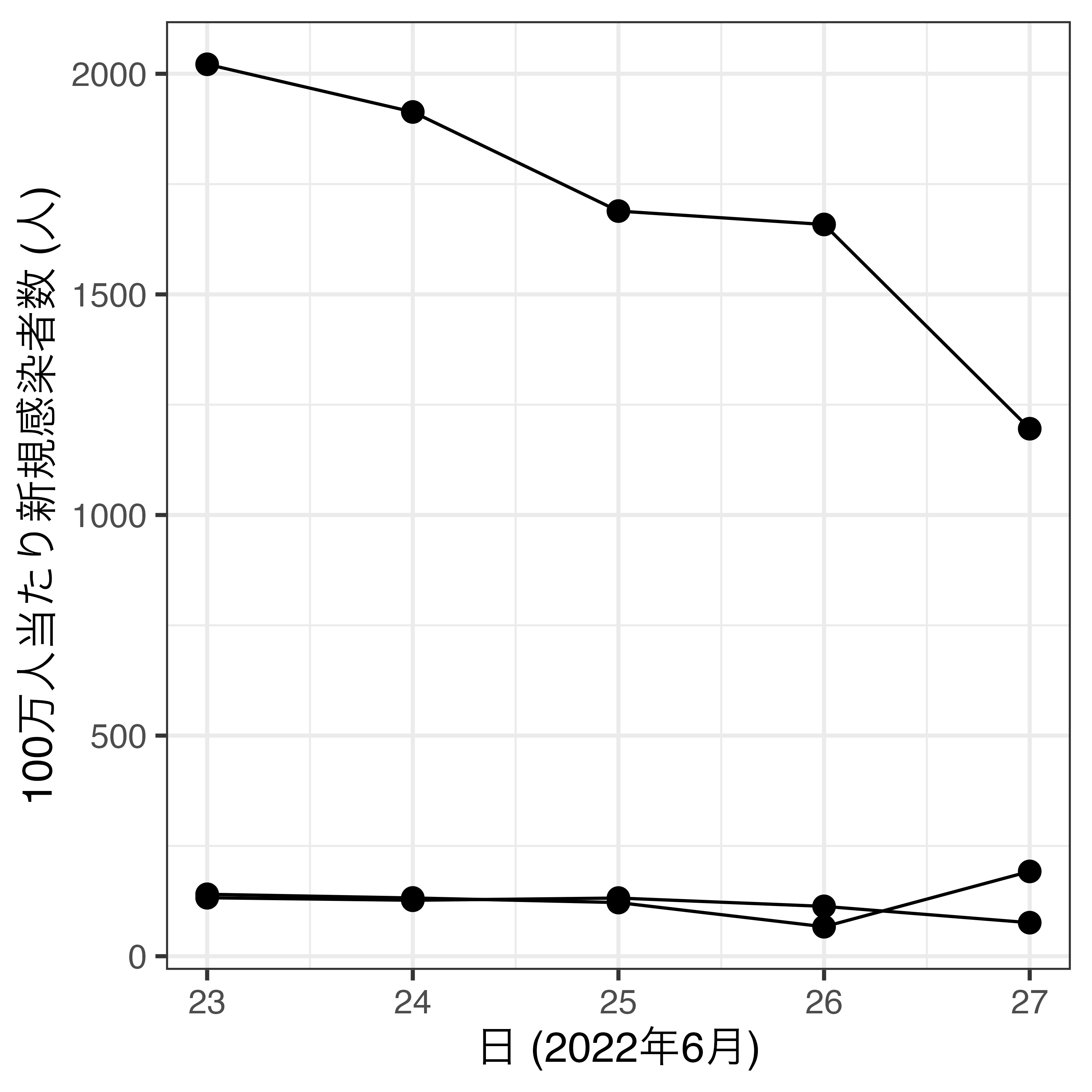
線が一本の場合
geom_line()幾何オブジェクトを使用
x: 点の傾きが変化し得る点の横軸上の位置y: 点の傾きが変化し得る点の縦軸上の位置- 日本の行のみを抽出し、横軸を日、縦軸を100万人当たり新規感染者数とした折れ線グラフを作成

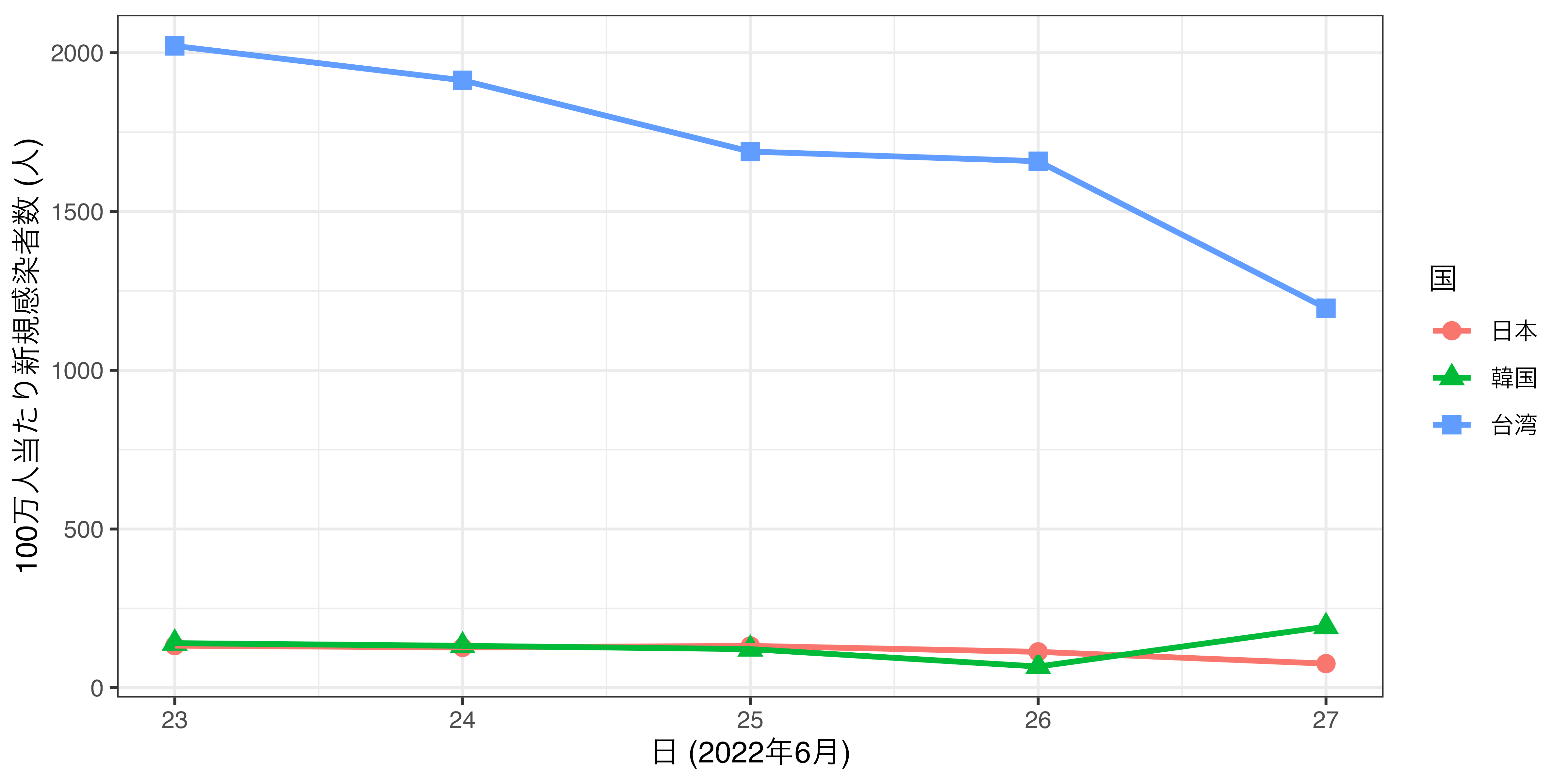
線が二本以上の場合
groupに線のグループ変数を指定
- 国別の折れ線グラフの場合、国変数を指定
COVID_df <- COVID_df |>
mutate(Country = case_when(Country == "Japan" ~ "日本",
Country == "Korea" ~ "韓国",
TRUE ~ "台湾"),
Country = factor(Country, levels = c("日本", "韓国", "台湾")))
COVID_df |>
ggplot() +
geom_line(aes(x = Day, y = NewCases, group = Country)) +
labs(x = "日 (2022年6月)", y = "100万人当たり新規感染者数 (人)")各線がどの国を示すのかが分からない…
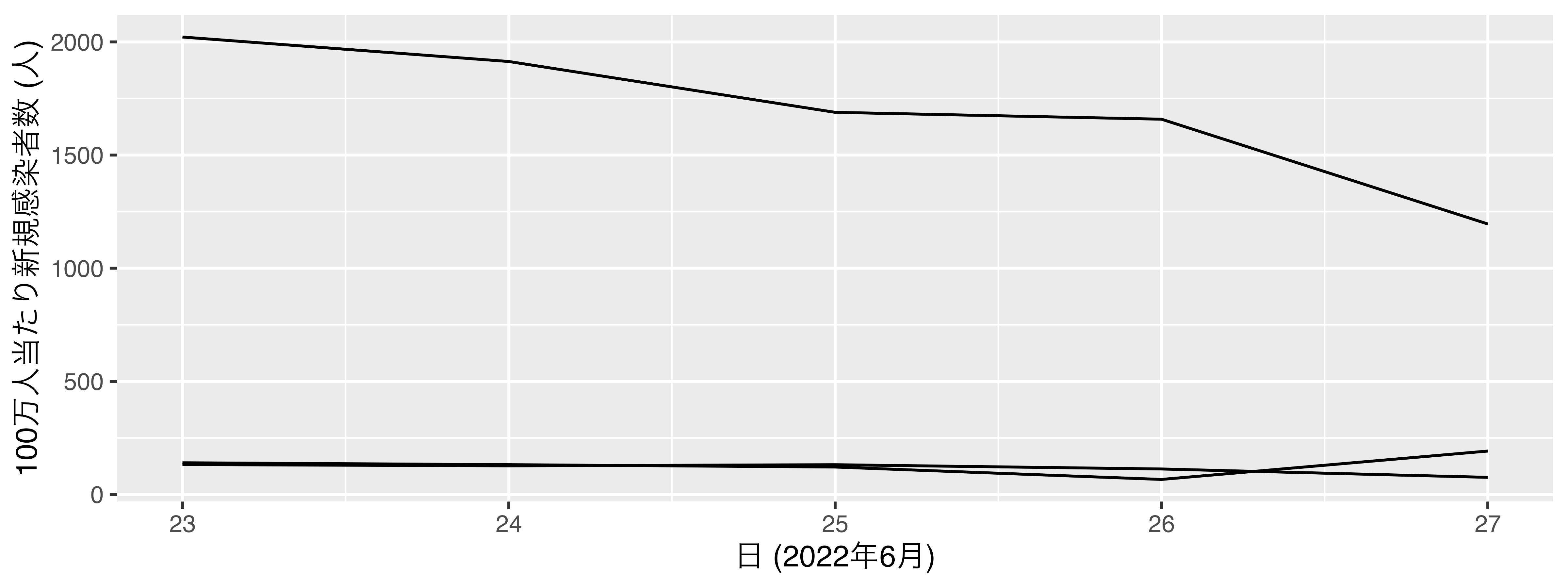
線が二本以上の場合
colorで色分け: 国別の折れ線グラフの場合、国変数を指定

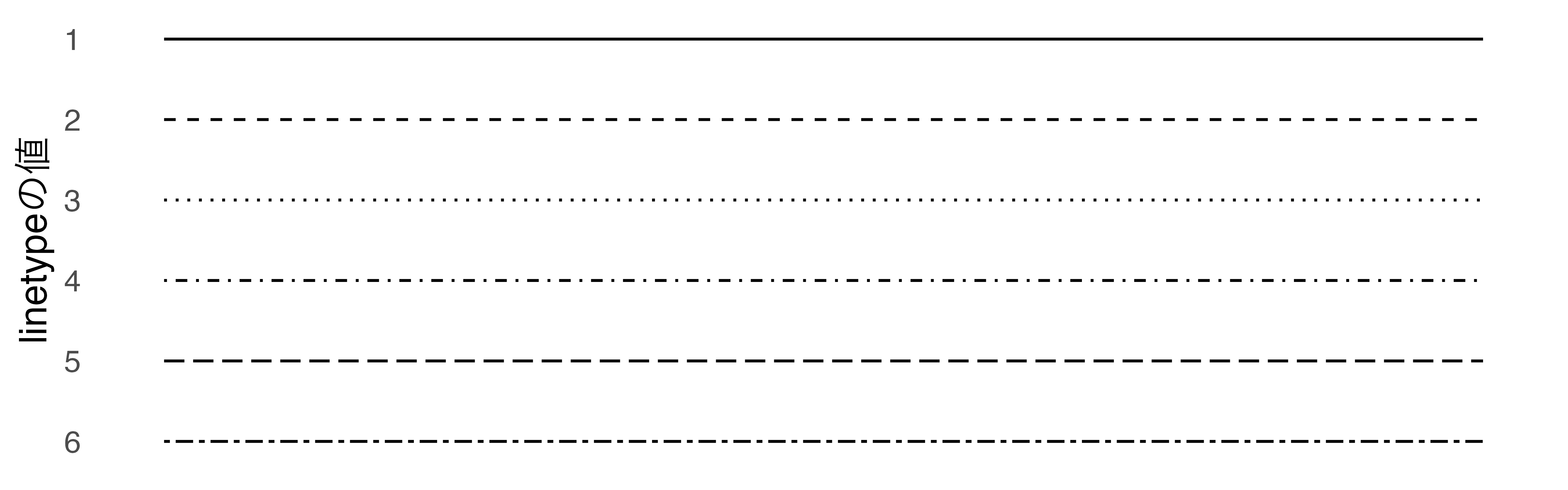
線のタイプ
- 主に白黒図で使用

linetypeの見本
種類が多くなると区別しにくいため、最大3つ程度
- 実線(1)、破線(2)、点線(3)
- 一つ面に登場する線は3〜4本程度まで(色分けも同様)
折れ線グラフ + 散布図(図)
箱ひげ図とは
変数の分布を示す方法の一つ
- 最小値、最大値
- ひげの両端
- 第一四分位数、第三四分位数
- 箱の上限と下限
- 中央値(第二四分位数)
- 箱内の線
- 外れ値がある場合、点
変数の分布をグループごとに見る時に有効
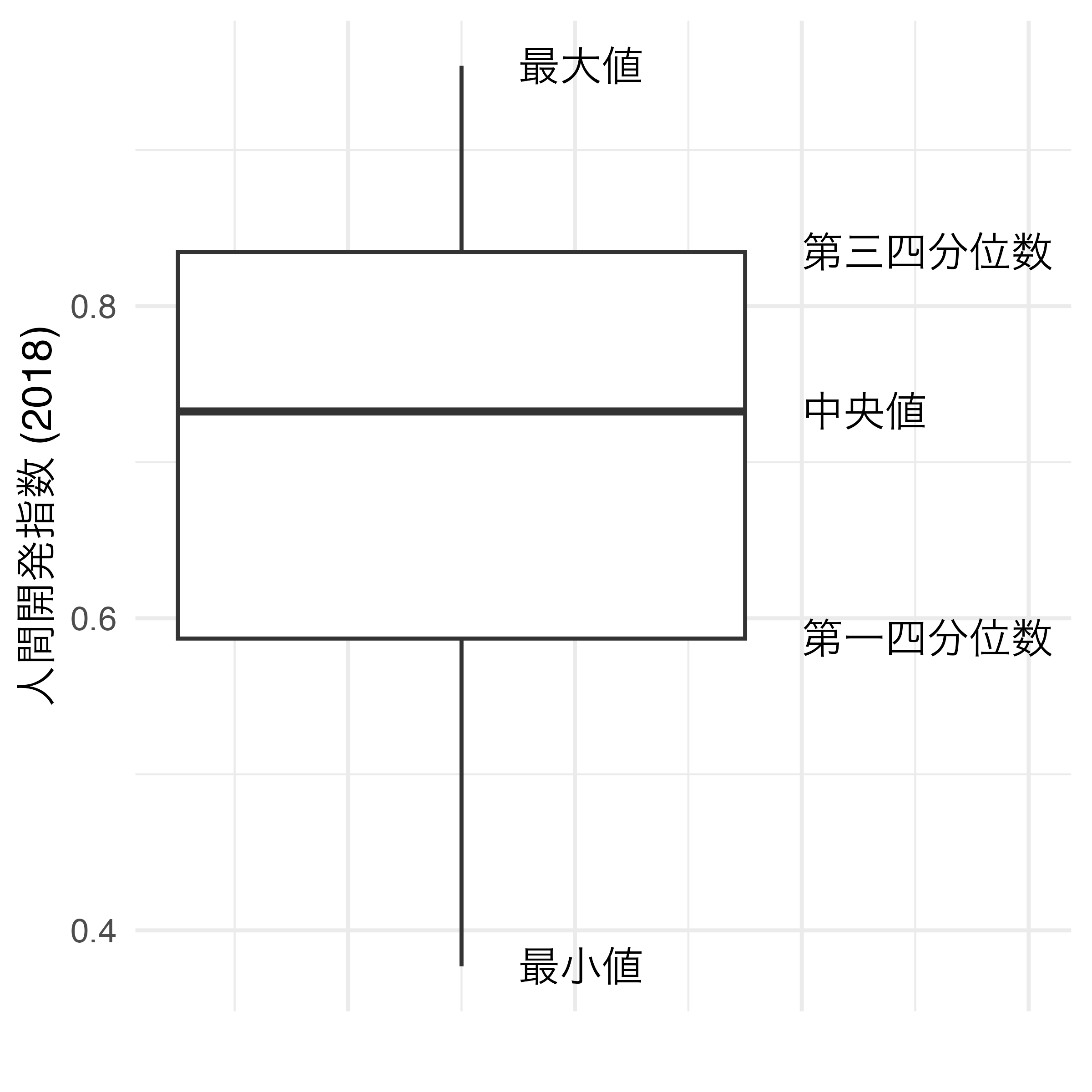
箱ひげ図の作成
人間開発指数 (HDI_2018) の箱ひげ図
x、またはyに分布を確認した変数をマッピングするxにマッピングするか、yにするかによって箱の向きが変わる

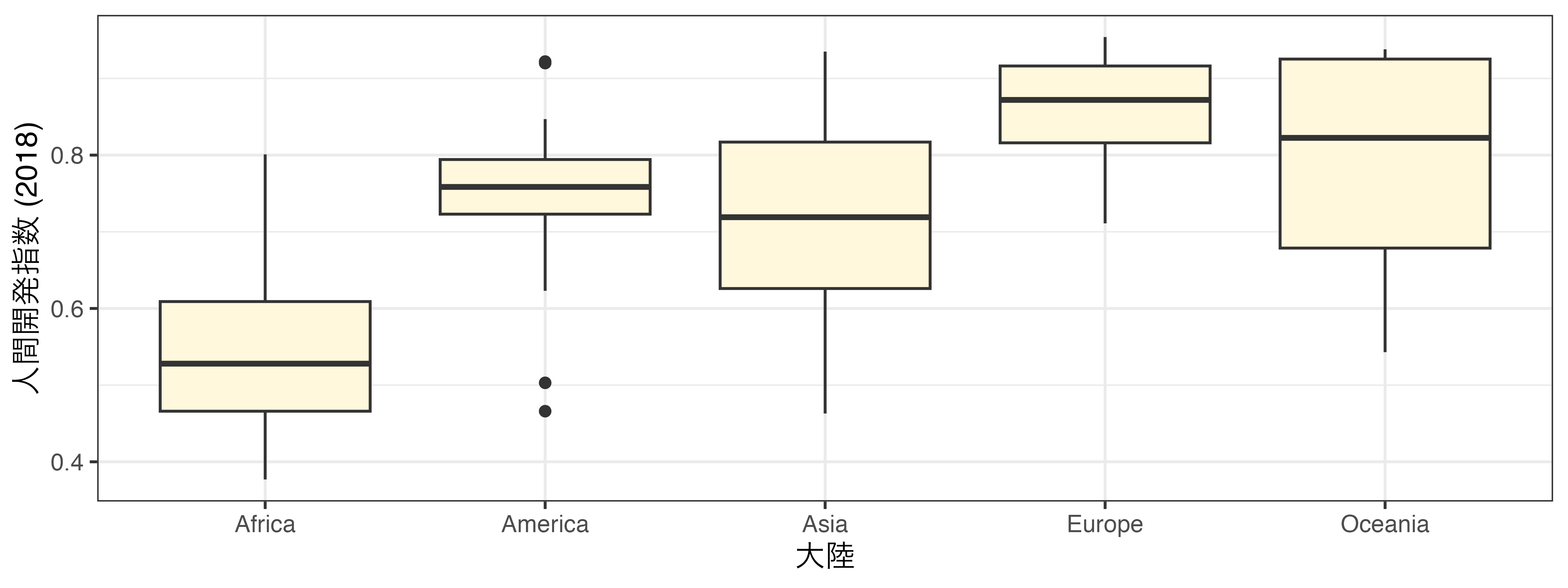
次元の追加
yにしかマッピングされているため、まだ次元追加の余地が残っている
xにマッピング(大陸ごとのHDI_2018の箱ひげ図)- 更に次元を追加したい場合は、ファセット分割

カスタマイズ(色)
箱の色を変える
- すべての色を変える場合、
aes()の外側にfill - 箱ごとにの色を変える場合、
aes()の内側にfill
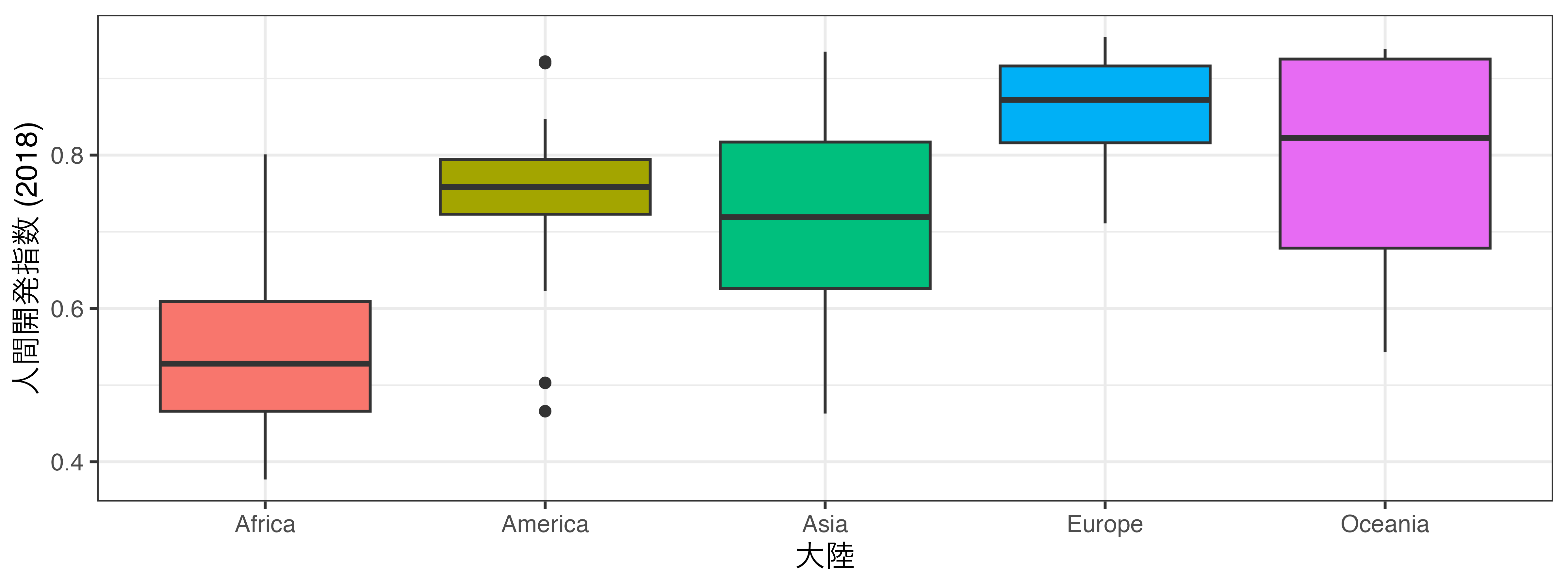
カスタマイズ(箱の幅)
aes()の外側にwidthを指定

横軸と縦軸の交換
箱が多すぎて読みにくい場合、xとyを交換も良い
